All the best for 2023 and that it may be a great and healthy year with more stability and peace than 2022!
The last almost two years I have not posted anything, simply because I did not have much time for it but also ais I did not really do anything noteworthy for a blog post. Currently I am working on several small projects again that probably will result in a post here about it.
Please note that I wil soon be moving my ancient Gitlab repository to something else (most likely Gitea as it seems to have all the features I need and is under active development). Links from this blog to my code may then change and I have not yet found a way to keep them working.
I will keep this short but expect to post some updates soon.
Yesterday I bumped into an interesting post on Hackster.io titled ESPCanary Detects If a Hacker Is Spying on Your Network about an Arduino library to turns an ESP8266 or ESP32 into a FTP Honeypot. This looks like an inexpensive and interesting option to detect intruders on your network.
I have been using TeamViewer for many years to support my relatives abroad when they had issues with their PC. I really like the product, despite getting huge (100Mb on MacOS) and bloated with many new features I don’t need, as it did the job well and worked cross-platform. For this reason, I have also always endorsed it for professional use with employers / customers (with the right paid license of course). However, as TeamViewer seems to have changed their strategy and seems to now aggressively push free users into a subscription they forced me to consider other options and switch to AnyDesk.
After my upgrade to vSphere Hypervisor 6.7 I (again) had to manually install the VMWare Tools for MacOS (and Solaris). VMware only includes the tools ISO images for Windows and Linux in the vSphere Hypervisor installer and during the installation process, any existing ISO image is removed.
As VMWare published version 10.3.0 of the VMWare Tools a few weeks ago, I will document in this (brief) post both the steps to upgrade VMWare tools on vSphere Hypervisor and the steps install the one for MacOS for future use.
I am running VMWare’s free vSphere Hypervisor (formerly known as ESXi) on my Mid-2011 Mac Mini Server (Macmini5,3) for many years . Earlier this year VMWare introduced vSphere Hypervisor 6.7 but as it was not really clear what it would add and I had a stable environment I decided not to upgrade (yet) when it came out.
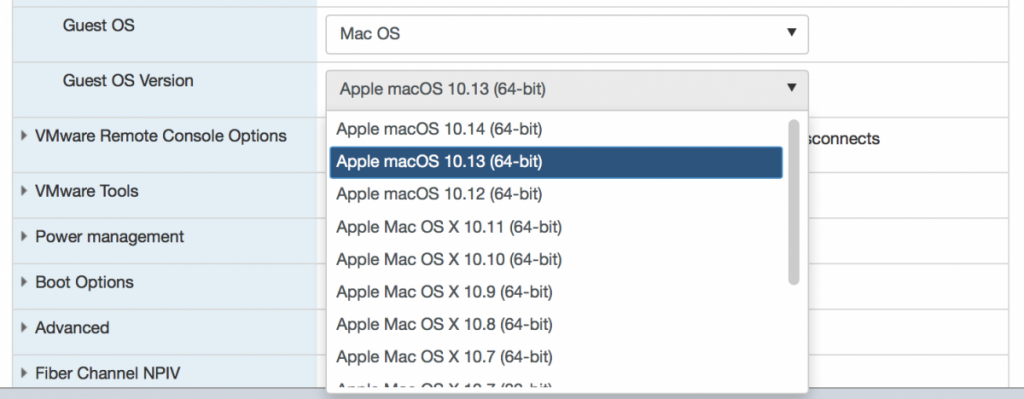
However, ever since Apple introduced the APFS filesystem with MacOS High Sierra, special care was required to install (or upgrade) a MacOS VM on vSphere Hypervisor as the built-in EFI boot did not support this. Since I had to create a new MacOS Server today, I decided to give this update a try to see if it would support MacOS High Sierra. Documentation was not very clear on this, but it turned out that with this version of vSphere Hypervisor, MacOS 12.13 (as well as 12.14!) is supported, as this is how the dropdown when creating a new VM now looks like for MacOS:
This post contains the steps to perform an upgrade from vSphere Hypervisor 6.5u1 to 6.7 on my Mid-2011 Mac Mini Server, including the installation of the (not included) VMWare Tools image for MacOS.
Today I noticed that VMWare has released a partial solution for the Spectre security issue ( CVE-2017-5715), according to VMWare:
This ESXi patch provides part of the hypervisor-assisted guest mitigation of CVE-2017-5715 for guest operating systems. For important details on this mitigation, see VMware Security Advisory VMSA-2018-0004.3.
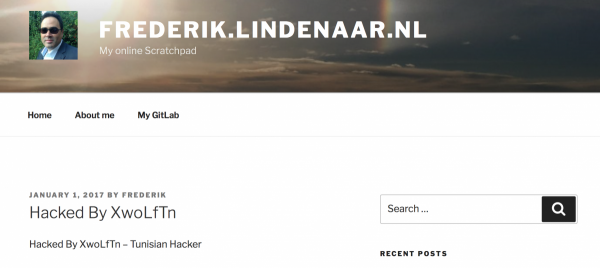
Today morning I noticed that my blog had been altered as it looked as displayed in the picture above. The first thing I did when I noticed this was to take my webserver offline until I could check what actually happened and to assess the impact of this breach of security. Fortunately the damage turned out to be very limited and easy to resolve so after a short research I was able to reconnect my webserver again and write about it. Continue reading ““Hacked” due to security issue in WordPress 4.7.1″
It’s a new year so the design of this blog has been refreshed as well. As I wrote a few weeks ago, some important things changed in my private live. On the short time it causes some stress and will be distracting me, but I have no doubts that this will be only for a short time. For now it means that I will probably have some more time for this blog and will be posting more frequent again, how this will develop on the longer term is still unsure.
For now I still have some time off to spend on my family and IT… keep posted for some updates the coming days. Anyway again all the best for this new fresh year!
After installing of OS X (MacOS) Sierra update 10.12.2 I noticed that SSH connections started to ask for the password of my RSA key. This wasn’t how it worked before and not what I want (as I trust my MacBook Pro) as it is quite annoying.
For the current session the solution was quite simple, just run the command: ssh-add -A
There seem to be many discussions online in what is causing this (i.e. here) with strange theories and odd (or not working) solutions. As documented also here, the root cause seems to be that the upstream OpenSSH code has changed and that Apple’s developers are following the changes.
The solution is fortunately quite simple: just create a file called ~/Library/LaunchAgents/org.openssh.plist with the following content:
For some time I have a small test network with a number of old Cisco routers (mainly 2500 series). Recently I decided to purchase a c1841 through Marktplaats as the IOS versions of the 2500 is really ancient and is very limited for more complex setups nowadays (latest IOS version is 12.3)
With the c1841 I also obtained two SHDSL cards, specifically:
a G.SHDSL WIC (WIC-1SHDSL-V3)
a 2-pair G.SHDSL HWIC (HWIC-2SHDSL)
These cards are described in detail on Cisco’s website. It turned out that the G.SHDSL HWIC card is supported in my main router (a c1921), so I decided to connect my test network to my main router using a DSL connection using these two cards to fully separate the test network from my main networks (and for the fun of it). Cisco had a good guide available to set this up (see Configuring Cisco G.SHDSL HWICs in Cisco Access Routers and Setup back to back CPE connection and ) but as it turned out not to be totally trivial I decided to document my setup here as well.
Cabling
The nice thing about (SH)DSL is that it uses standard phone (CAT-4) cables that can be up to several kilometers long. For my test lab I started off with a standard (2-wire) phone cable with 6-pin RJ-11 connectors. (SH)DSL uses a straight connection where one of the ends should be put in CPE (subscriber) mode and the other one in CPO (office) mode.
As the 2-pair G.SHDSL HWIC (HWIC-2SHDSL) interface has two ports and I temporarily had two c1841 routers with a G.SHDSL WIC (WIC-1SHDSL-V3) I also created a splitter cable as per the Cisco G.SHDSL documentation (diagram below) to establish two DSL connections.
SHDSL RJ-11 splitter schematic
Dual DSL connection with 2 wires using a splitter cable
With the above cable it was quite easy to establish DSL connections between my c1921 router with the 2-pair G.SHDSL HWIC (HWIC-2SHDSL) card and two c1841with an G.SHDSL WIC (WIC-1SHDSL-V3) adapter. Unfortunately the 2-pair G.SHDSL HWIC (HWIC-2SHDSL) can only operate in CPE (client) mode so c1921 was running in CPE mode for both lines and the two c1841s both need to be set to CPO (office) mode. This setup looks like this:
Below is the configuration used:
c1921 with 2 DSL connections to 2 c1841s:
controller SHDSL 0/0/0
dsl-group 0 pairs 0
!
dsl-group 1 pairs 1
!
!
interface ATM0/0/0
no ip address
no atm ilmi-keepalive
pvc 0/35
encapsulation aal5snap
!
pvc 8/35
encapsulation aal5mux ppp dialer
dialer pool-member 2
!
!
interface ATM0/0/1
no ip address
no atm ilmi-keepalive
pvc 0/35
encapsulation aal5snap
!
pvc 8/35
encapsulation aal5mux ppp dialer
dialer pool-member 3
!
!
interface Dialer1
ip unnumbered GigabitEthernet0/0
encapsulation ppp
dialer pool 2
dialer-group 2
!
interface Dialer2
ip unnumbered GigabitEthernet0/0
encapsulation ppp
dialer pool 3
dialer-group 3
!
dialer-list 2 protocol ip permit
dialer-list 3 protocol ip permit
Obviously in a real-live setting additional statements will be required to ensure that firewall, nat, etc. are also correct but that is not the intention of this description. The above sets up the SHDSL adapter in 2-line more and defines two ppp connections over ATM and uses the IP address of the main GigabitEthernet interface also for the dialer interfaces. The corresponding configuration on the two c1841s is:
c1841 with DSL connections to c1921 (two times):
controller DSL 0/0/0
mode atm
line-term co
dsl-mode shdsl symmetric annex B
!
interface ATM0/0/0
no ip address
no atm ilmi-keepalive
pvc 0/35
encapsulation aal5snap
!
pvc 8/35
encapsulation aal5mux ppp dialer
dialer pool-member 1
!
!
interface Dialer0
ip unnumbered Loopback0
encapsulation ppp
dialer pool 1
dialer-group 1
!
ip route 0.0.0.0 0.0.0.0 Dialer 0
!
dialer-list 1 protocol ip permit
!
This (re)uses the IP address of the Loopback0 interface for the dialer interface. Thanks to the default route all 3 Cisco’s will be able to reach each other. During the simple speed tests I was able to do I noticed that the DSL connection could almost reach it’s 2Mbit maximum throughput, even from one c1841 through to c1921 to the other c1841. For more complex routing I would recommend not using static routes but using a routing protocol like EIGRP (which I am using as well and will describe later).
Single DSL connection with 4 wires using a straight cable
As one of the c1841s was a loaner, I then decided to setup the permanent connection slightly different using a 4-wire cable and configured the c1921 and c1841 slightly differently to utilise all 4 wires of the cable. The benefit of this setup is that it doubles the connection speed to approx. 4.5Mbit (still not really amazing considering that my internet connection over fiber cable is 50Mbit, but a bit more). This setup looks like this:
Below is the configuration used:
c1921 4-wire DSL connections to c1841:
controller SHDSL 0/0/0
dsl-group auto
shdsl 4-wire mode enhanced
!
!
interface ATM0/0/0
no ip address
no atm ilmi-keepalive
pvc 0/35
encapsulation aal5snap
!
pvc 8/35
encapsulation aal5mux ppp dialer
dialer pool-member 2
!
!
interface Dialer1
ip unnumbered GigabitEthernet0/0
encapsulation ppp
dialer pool 2
dialer-group 2
!
This setup is pretty similar to that before apart from how the SHDSL controller is configured and there is also (due to this configuration) only 1 ATM interface (so also only Dialer interface needed). However, as the controller is changed it is required to issue the following command to remove the previous dsl-group definitions to switch from the previous setup:
controller SHDSL 0/0/0
no dsl-group 0
no dsl-group 1
Before this new configuration can be entered, which also removes all configuration of the ATM interfaces (the Dial interfaces are unaffected). The corresponding configuration on the c1841 is:
c1841 4-wire DSL connections to c1921:
controller DSL 0/0/0
mode atm
line-term co
line-mode 4-wire enhanced
dsl-mode shdsl symmetric annex B
!
interface ATM0/0/0
no ip address
no atm ilmi-keepalive
pvc 0/35
encapsulation aal5snap
!
pvc 8/35
encapsulation aal5mux ppp dialer
dialer pool-member 1
!
!
interface Dialer0
ip unnumbered Loopback0
encapsulation ppp
dialer pool 1
dialer-group 1
!
ip route 0.0.0.0 0.0.0.0 Dialer 0
!
dialer-list 1 protocol ip permit
!
With this new configuration early measurements indeed confirm the bandwith is higher, but not really doubled. As this is a connection to my test network, the performance is not really an issue but I like the idea of having physical cable that I can remove easily and the fact that my test network is not connected to my main switch / network in any way.